最近阿里通义团队新开源了一个文生图模型 Tongyi-MAI/Z-Image-Turbo,官方介绍这是一个蒸馏版 (Distilled) 模型,仅需 8 步推理 (8 NFEs) 即可生成高质量图像,也就是说,可以在消费级显卡上流程运行。最近,我也在 Google Colab 平台上试了试。
介绍
首先介绍下这个模型
参数:
- 名称:Z-Image-Turbo
- 类型:文本到图像生成模型 (Text-to-Image)
- 参数:60亿 (6B)
- 架构:可扩展的单流 DiT (Scalable Single-Stream DiT, S3-DiT)
- 开源许可:Apache-2.0
亮点:
- 极致效率:蒸馏模型,8 步推理即可生成高质量图像。
- 中英双语支持:擅长处理复杂的中文和英文文本渲染,准确地按照指定的文字内容生成图像。
- 写实风格:专注于生成照片级逼真 (Photorealistic) 的图像,同时保持优秀的审美质量。
- 强大的指令遵循:能够很好地理解和执行用户的 Prompt 指令。
而我刚好前段时间在X上也刷到很多相关资讯,看到的生成效果在这个参数量级感觉已经很不可思议了,从观感上而言,个人认为效果非常不错,今天就来试试这个模型到底怎么样。
部署
因为我不怎么玩游戏,所有我也没有游戏主机,自然也没有还不错的消费级显卡,那就只能去租用平台算力。经过搜索以及反复比较,也考虑到网络要求的相关,最终选择了 Google Colab 算力平台,毕竟G家也是有自身硬实力(TPUs)的对吧。
Pro套餐每月包含100点算力也足够我日常轻度使用了,订阅费用为$9.9/mo,当然也可以使用US教育邮箱做学术认证方可使用,我这里采用了后者订阅方式,大家可以根据自身所需选择合适的套餐订阅使用。
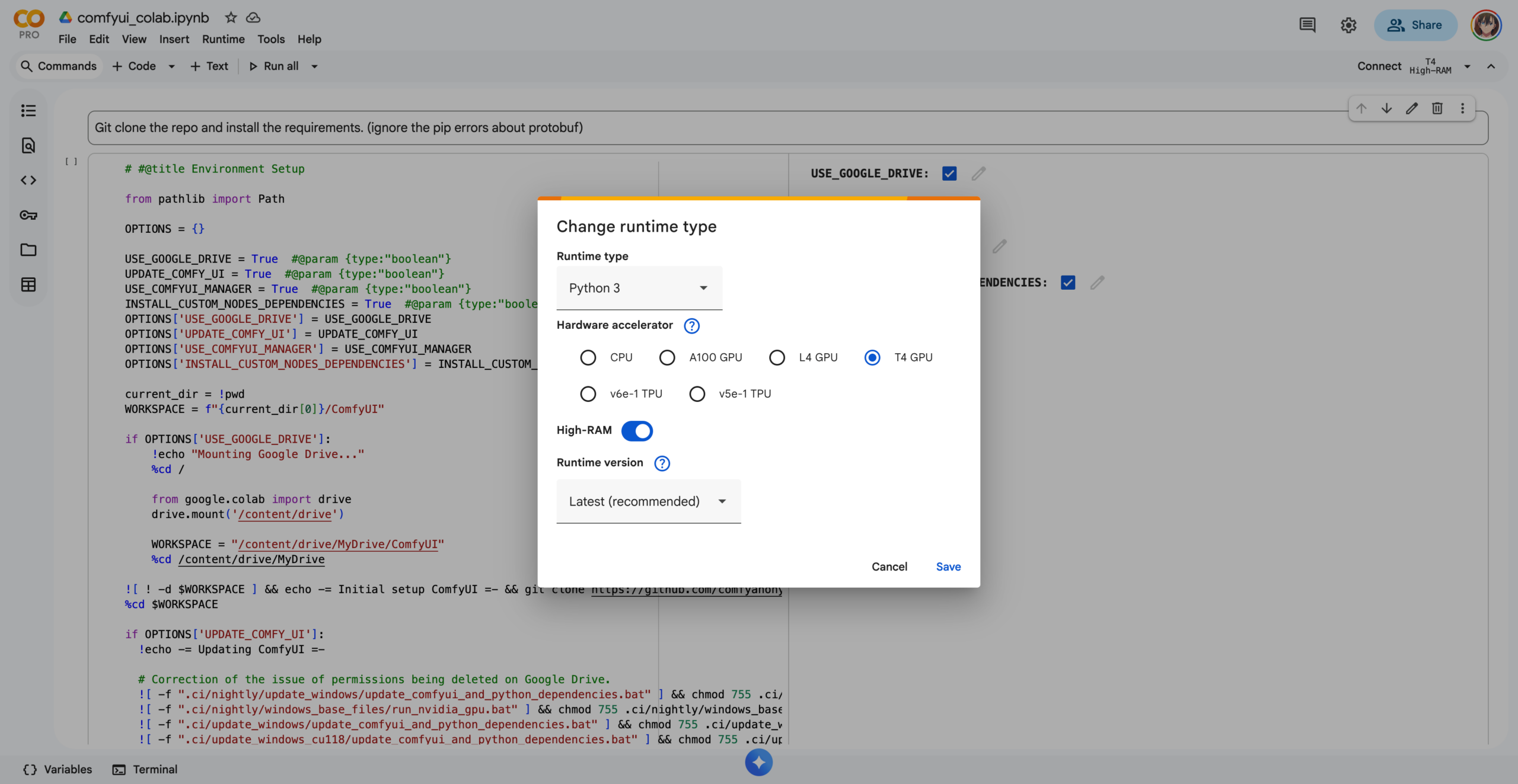
开通后访问 https://colab.research.google.com/ 就可以开始使用了,引入来自 ComfyUI-Manager 官方项目中的 .ipynb 文件到Colab Workspace,右上角选择对应算力运行类型,里面主要是环境和GPU选择,经济考虑,我这里选择了T4 GPU搭配High-RAM(51GB),内存一定要选择上Hight-RAM,就拿一个有 70 亿参数的模型,如果用 FP16,光权重就要占有大约 14GB 内存,更别说还有推理过程的占用了。
基于上图中这套配置,使用成本大约在1.41 per hour左右,也就是说,100点能够不停歇给你提供约71小时的算力使用。确认好配置后点击右上角Connect连接到你的算力实例,就可以开始部署ComfyUI了。
运行第一段代码,会提示连接到你的Google Drive,这是因为Colab只给你提供算力以及临时存储空间,而你的所有文件包括模型最终都需要下载到你的Drive中进行持久化存储,只是在使用Colab过程中可以临时挂载到算力实例上面。第一段代码运行完毕大约需要4分钟,在这过程中主要是配置Google Drive集成,安装ComfyUI以及对应的一些必要环境和依赖。
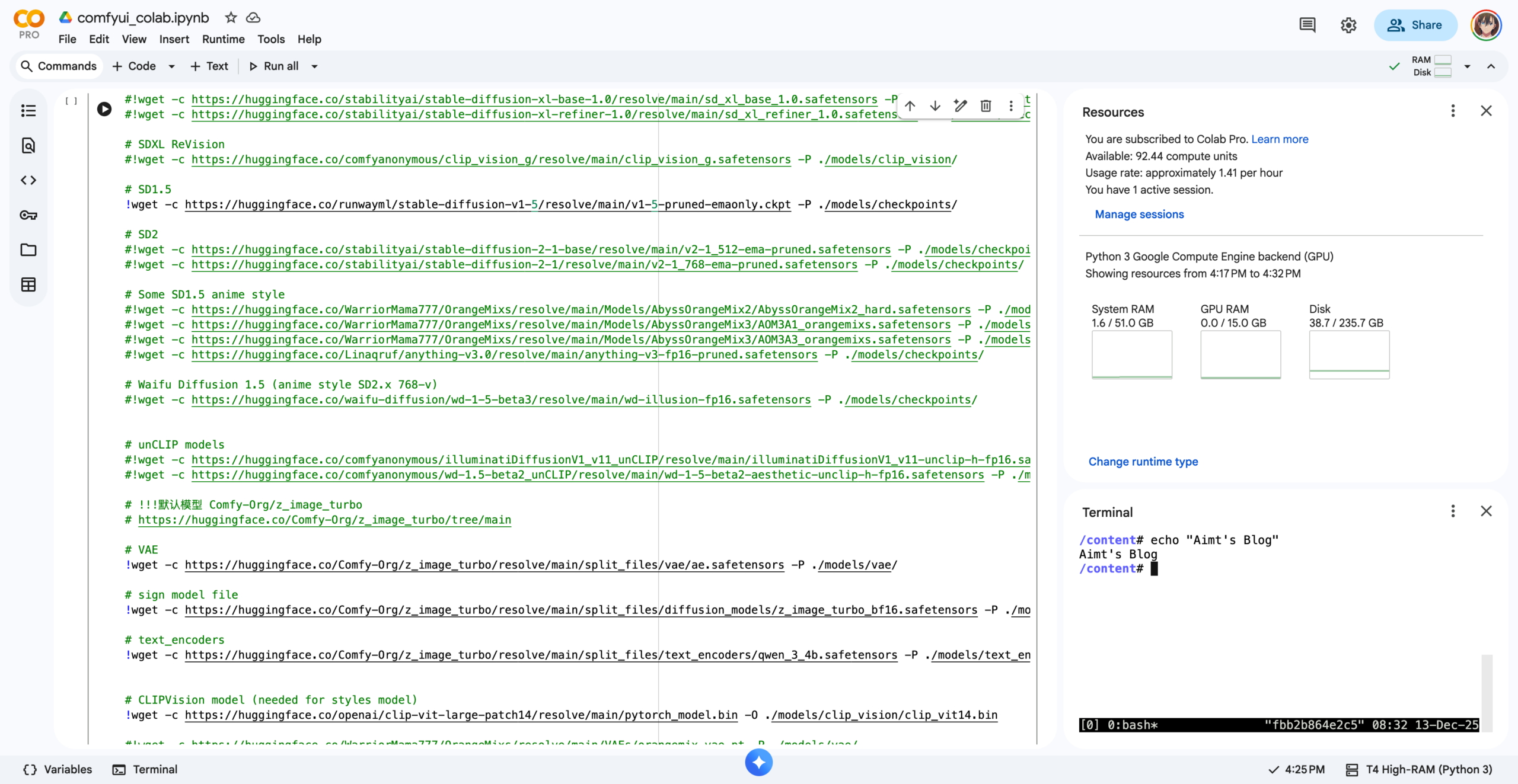
接着开始运行第二段代码,这里核心内容是下载Z-Image-Turbo的模型文件,我这里配置了来自Huggingface平台上的Comfy-Org/z_image_turbo模型,可以在 https://huggingface.co/Comfy-Org/z_image_turbo/tree/main 找到,此处下载了三部分文件:
- Stable Diffusion 1.5
- CLIP Vision
- z_image_turbo 相关组件
- VAE(变分自编码器)
- Diffusion Model(扩散模型本体)
- Text Encoder(文本编码器)
由于我在之前已经提前下载过了,保存到了Google Drive中,所以再次运行ComfyUI时无需重复下载。
接下来就是运行第三块代码,这里核心负责启动ComfyUI,并且通过 Google Colab 提供的端口转发功能,将实例内的本地端口转发到可以公网访问到的地址上,当你看到以下这部分黑色的ComfyUI界面时,就说明启动成功了。
继续往下查看日志,可以看到:
[ComfyUI-Manager] All startup tasks have been completed.这样一行关键字,以及一个网页地址链接,点击这个网页地址,就可以调整到你的ComfyUI平台了。是一个类似 xxxxx.xxx.prod.colab.dev 这样的地址。
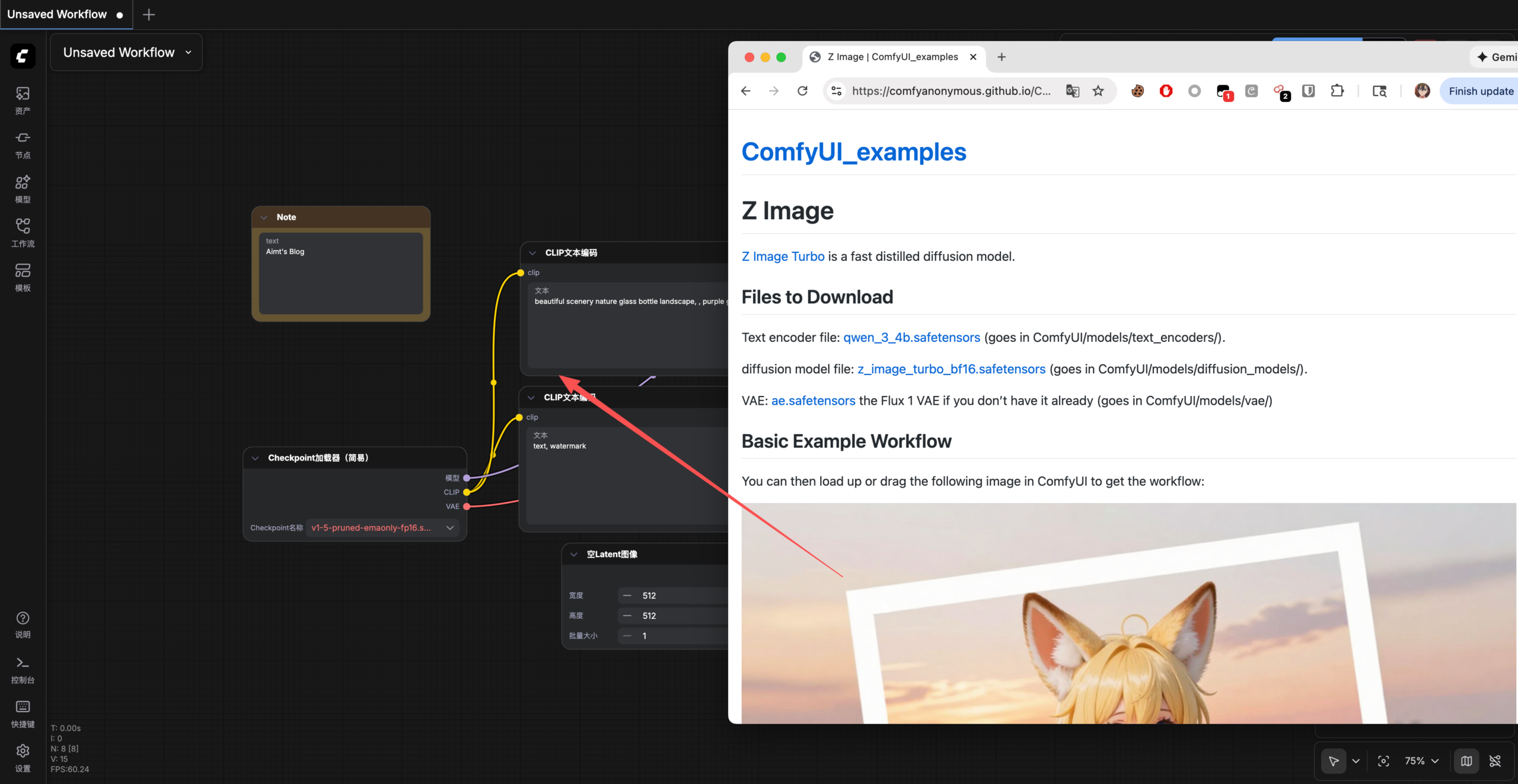
接着我们将由 https://comfyanonymous.github.io/ComfyUI_examples/z_image/ 提供的 Z Image 工作流示例图片直接拖动到我们ComfyUI中。
如果一切顺利,这里将直接加载好对应的模型文件了,然后就可以开始体验Z-Image-Turbo模型了,可以直接点击右上角的运行进行初始化,初次运行会耗时比较长,大约需要5分钟,因为需要加载模型。
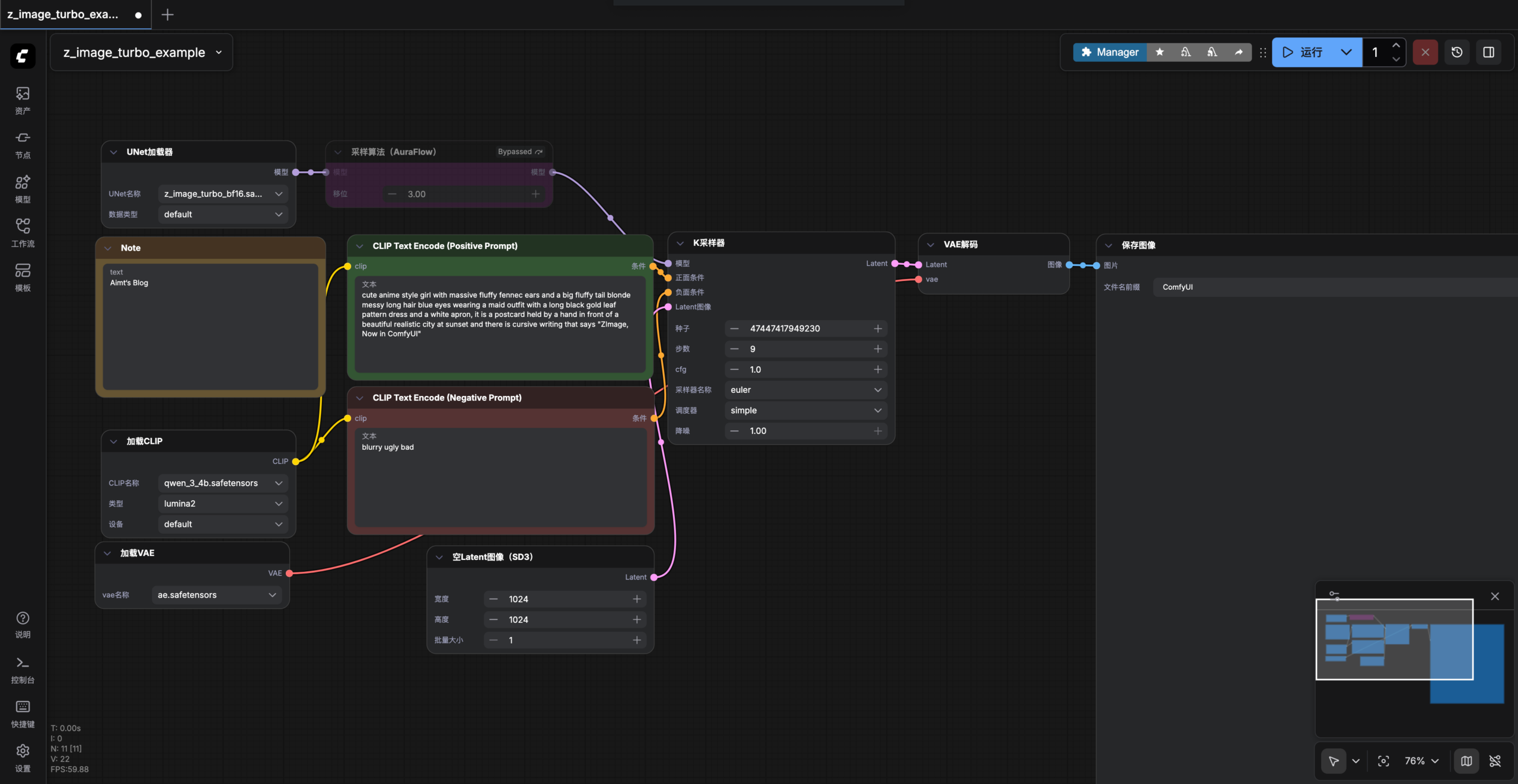
体验
接着就可以正常使用了,我先使用简单的提示词来尝试一下生成效果。经过了5分钟的初始化,后续在生成1920*1080分辨率图片时,一张大约在90s的样子,考虑到这块Tesla T4 GPU的性能参数,还算能够接受。
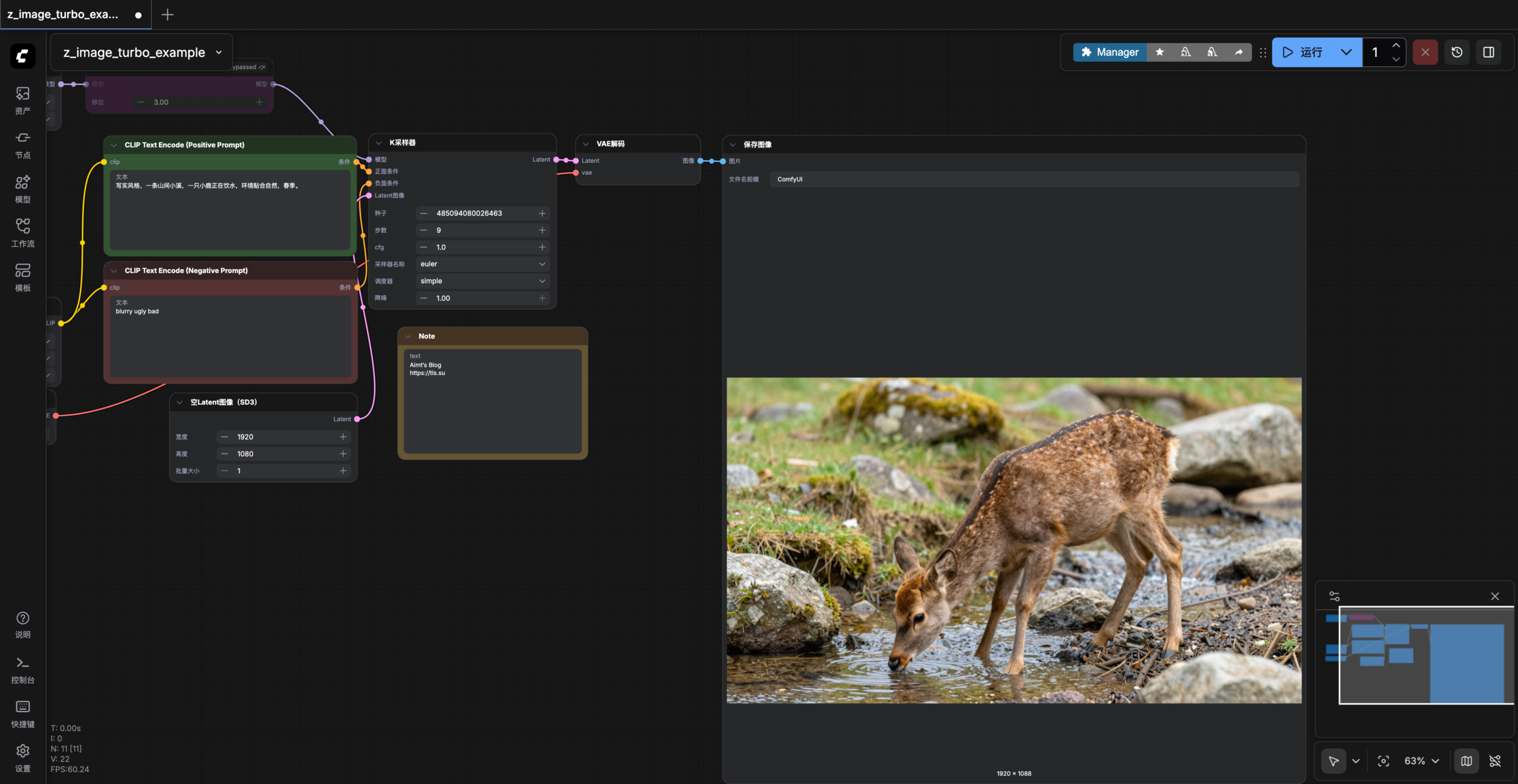
写实风格,一条山间小溪,一只小鹿正在饮水,环境贴合自然,春季。

一位徒步登山者穿着专业登山装备以及徒步背包走在山脊上,长焦镜头视角,镜头背景是巍峨的雪山。

F1比赛场,观众视角,专业车手驾驶赛车在赛道上你追我赶,现场的观众也将比赛氛围推向了赛点高潮。

清晨,雾还没散去,隐约从山里延展了一条道路出来,围绕在半山腰,没有一辆车也没有一个人,安静、孤寂的感觉。
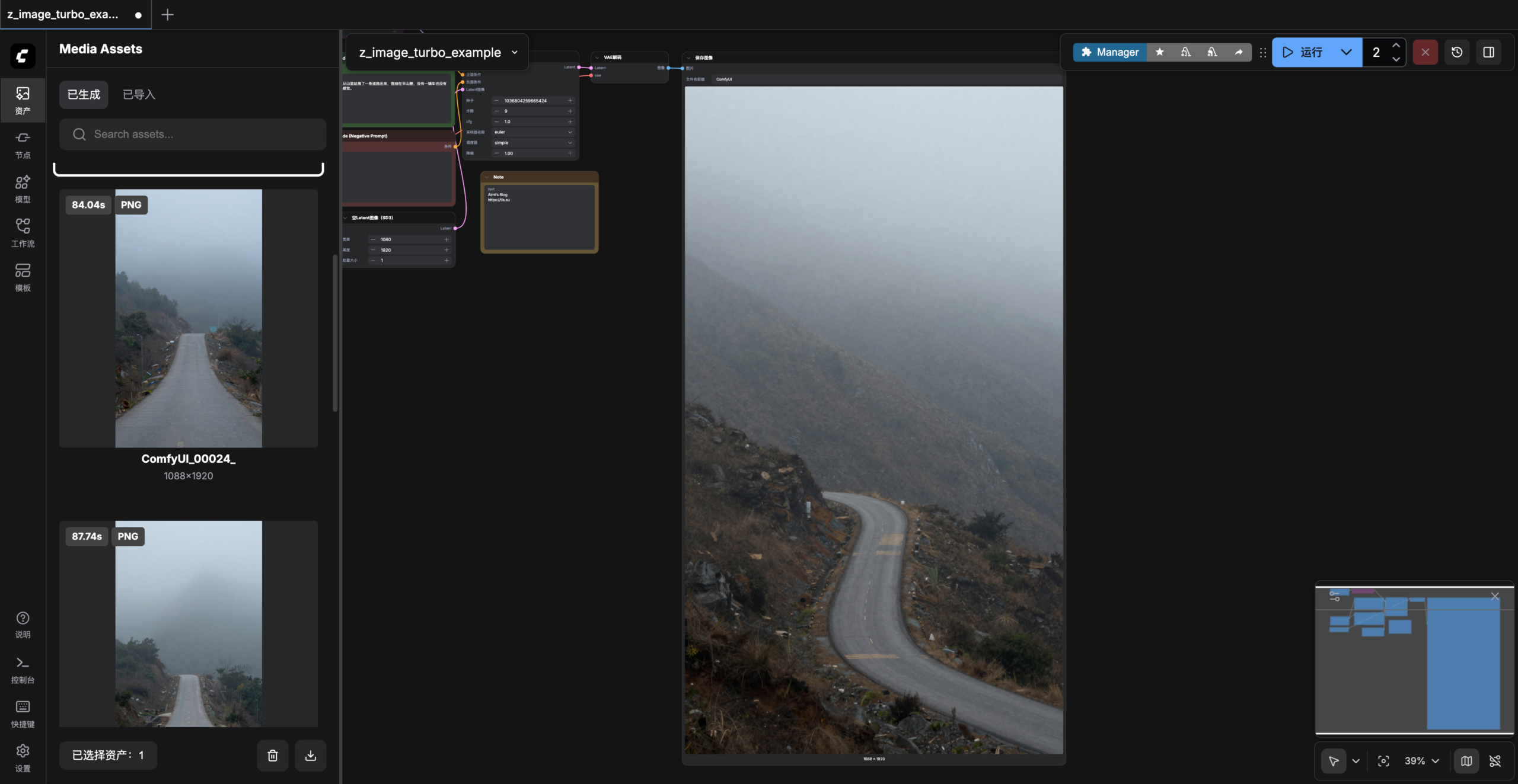
通过简单描述下场景,就能生成出如此惊艳的图片,有点出乎我的意料了。甚至我已经无法分辨出这是由AI生成的图片,一眼看去和实际拍摄的照片几乎没有两样。发给朋友看也觉得不可思议,他也尝试本地部署进行了体验,4080s出图1080P大约9秒钟一张,比这块T4 GPU要快不少。
闲聊
当今AI的迅速发展也令人感慨,回想三年前22年11月底,ChatGPT的GPT-3.5初次出现在大家视野中,为普通人提供了追寻答案的捷径。再次之前的印象中,AI好像离我们特别遥远,只是模糊记得有一些神经网络模型、视觉神经模型,用作一些很简单且单一的场景,也根本没能想到有一天会像一个人一般出现在我的手机、电脑里,可以24小时随叫随到解决你的问题。三年后的今天,AI几乎已经走进了每一个普通人的视野里,工作中、生活中,扮演着各种各样的角色,这对于人类的进步无疑是巨大的
我在前段时间抽空看完Joe Rogan 和马斯克的 3 小时访谈,里面Elon Musk提到了未来AI发展可能的趋势,比如未来不再会有操作系统或者应用程序,所有的操作、应用交换都只需要用自然语言去实现,调用系统各大平台的MCP或者接口,不再需要我们手动耗费精力去操作设备;也聊到了AI 边缘节点这个概念, 传统意义上的手机将演变成一个用于 AI 推理的边缘节点,随地随地进行实时计算,尽可能多的在手机或各种设备上运行AI,减少与服务器直接的带宽已经算力。我无法想象未来会变成什么样子,有了AI和机器人,真的能让普通人去过更有意义的生活吗?或许,这些都只是理想的社会主义乌托邦,资本家即使有这样的能力,也不会开放给消费者使用,社会与经济的全面富足不是资本家愿意看到的场面,就像他们不希望普通人快速完成原始资本累积一样。
原创内容,转载请注明出处:https://tls.su/archives/7
发表回复